Artificial intelligence (AI) is increasingly being integrated into our daily lives. For instance, many of us might have ...
Artificial intelligence (AI) is increasingly being integrated into our daily lives. For instance, many of us might have an Alexa powered device in our homes, or we might use Siri on our iPhones. However, since the public launch of ChatGPT late last year, there is a widely-shared sense that the trajectory of AI is rapidly accelerating.
Indeed, in March 2023, Bill Gates declared on his blog that “The Age of AI” has begun. He writes:
The development of AI is as fundamental as the creation of the microprocessor, the personal computer, the Internet, and the mobile phone. It will change the way people work, learn, travel, get health care, and communicate with each other. Entire industries will reorient around it. Businesses will distinguish themselves by how well they use it.
The key point is that AI will soon become an inextricably essential part of daily life. As such, concerns about the security of AI systems will only heighten. It makes sense, therefore, to carefully study this problem.
It is a big problem. This has to do with the nature of AI systems. AI systems have many parts. At a minimum, the components of an AI system include its data, model, procedures for training, testing, and deploying machine learning (ML) models, and the infrastructure required for all of this. There are several kinds of data modalities, many kinds of models, and many kinds of procedures for training, testing, and deploying ML models, not to mention many possibilities when it comes to architecting the infrastructure involved. As such, it should not be surprising that a wide range of effective attacks against AI systems exist.
Towards getting a grip on the problem of securing AI systems, it would be useful to develop a high-level framework for classifying and categorizing attacks, not least for the important purpose of standardizing terminology to be used by the AI and cybersecurity communities. To this end, in March 2023, NIST published AI 100-2e2023 ipd, titled, “Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations.” The purpose of this blog post is to take a look at the taxonomy developed by the authors of this report, as seen in Figure 1.
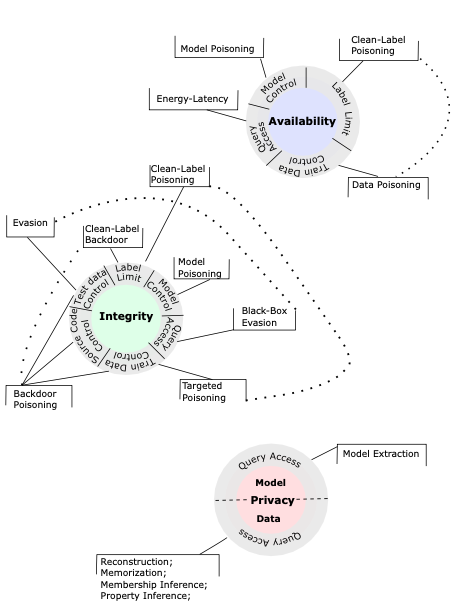
Attack Objectives
The CIA Triad is a benchmark model used to evaluate a system’s security. The three attributes of a system that are assessed in the model are confidentiality, integrity, and availability. At a high level, NIST AI 100-2e2023 classifies attacks on AI systems by considering which one of these attributes an attacker is most interested in breaking down. In Figure 1, each of these attributes is at the center of its own circle.
-
Privacy compromise - the principle of confidentiality states that data should not be accessed without authorization. In other words, data should be private. The objective of privacy compromise attacks on AI systems, thus, is to learn information about the training data or about the ML model. There are many kinds of privacy attacks, which we examine below.
-
Integrity violation - the principle of integrity states that data should not be modified by unauthorized entities. In integrity violation attacks, the objective is to target the ML model’s output, so that it produces incorrect predictions. Integrity violations can be carried out by mounting an ‘evasion attack’ or a ‘poisoning attack,’ both of which we discuss below.
-
Availability breakdown - the principle of availability states that data should be accessible to authorized users. It follows that in an availability breakdown, an attacker attempts to break down the performance of the model at the testing or deployment phase. These kinds of attacks use ‘poisoning’ techniques, discussed below.
Attacker Capabilities
To achieve one of the objectives discussed above, NIST AI 100-2e2023 lists six types of capabilities that might be leveraged by an attacker. These refer to the general strategies that might be used by an adversary to achieve their overall objective. In Figure 1, we can see these capabilities on the outer layer of each circle. Let’s quickly run through each one of these.
-
Training data control - the attacker takes control of a subset of training data, by inserting or modifying training samples.
-
Model control - the attacker takes control of model parameters, by inserting a Trojan in the model or by sending malicious local model updates in a federated learning setup.
-
Testing data control - the attacker adds perturbations to testing samples at model deployment time.
-
Label control - the attacker controls labels of training samples (in supervised learning).
-
Source code control - the attacker modifies the source code of the ML algorithm, especially open-source components like third-party libraries.
-
Query access - the attacker submits queries to models that are managed by a cloud provider.
Note - as illustrated in Figure 1 - that query access is the capability exclusively leveraged in privacy compromise attacks. In integrity violations, an adversary could make use of any of the six capabilities listed above. Finally, in availability breakdowns, an attacker would need model control, label control, training data control, or query access.
Attacker Knowledge
An important consideration, in categorizing attacks, is the level of knowledge an adversary has about the AI system. There are three possibilities: white-box attacks, black-box attacks, and gray-box attacks.
-
White-box - the attacker operates with complete knowledge of the AI system.
-
Black-box - the attacker operates with minimal knowledge of the AI system.
-
Gray-box - the attacker operates with some knowledge of the AI system.
Attacker knowledge is an important dimension in attack classification because it impacts the kind of attack that an adversary can mount. This is perhaps most evident in evasion attacks, which are discussed below.
Evasion Attacks
In an evasion attack, the goal is to generate ‘adversarial examples,’ which are testing samples whose classification can be changed by the attacker at deployment time with minimal impact. NIST AI 100-2e2023 identifies several ways this might occur: optimization-based methods, universal evasion attacks, physically realizable attacks, score-based attacks, decision-based attacks, and transfer attacks.
-
Optimization-based methods - the attacker, knowledgeable of the ML model, computes gradients relative to the model’s loss function, with the intent of generating adversarial examples at a small distance from the original testing samples.
-
Universal evasion attacks - the attacker constructs small universal perturbations which can be added to data - in particular, to images - to induce a misclassification.
-
Physically realizable attacks - the attacker targets AI systems in a way that is realizable in the physical world, for instance, by applying black and white stickers to road signs so as to evade a road sign detection classifier.
-
Score-based attacks - the attacker obtains the model’s confidence scores or logits by query, and uses optimization techniques to create adversarial examples.
-
Decision-based attacks - the attacker obtains the final predicated labels of the model, and uses various techniques, such as optimization techniques, to create adversarial examples.
-
Transfer attack - the attacker trains a substitute ML model, generates attacks on it, and transfers the attacks to the target model.
Note that optimization-based methods, universal evasion attacks, and physically realizable attacks are considered white-box attacks. Score-based attacks and decision-based attacks are considered white-box attacks.
Poisoning Attacks
Broadly defined, poisoning attacks are attacks that target the training stage of an ML algorithm. These kinds of attacks can be launched with the goal of compromising the availability and/or the integrity of an AI system. At a high level, NIST AI 100-2e2023 categorizes poisoning attacks into one of four kinds: availability poisoning, targeting poisoning, backdoor poisoning, and model poisoning.
-
Availability poisoning- the attacker causes indiscriminate degradation of the ML model on all samples, effectively causing a denial-of-service.
-
Targeted poisoning - the attacker induces a change in the ML model’s prediction on a small number of targeted samples.
-
Backdoor poisoning - the attacker introduces a small patch trigger in a subset of training data, and changes their label to a target class.
-
Model poisoning - the attacker attempts to directly modify the trained ML model by injecting malicious functionality into it.
Privacy Attacks
Adversaries launch privacy attacks with the goal of compromising the confidentiality of an AI system. In other words, the objective of privacy attacks is for the attacker to have access to otherwise privileged data, in particular the training data or ML model. NIST AI 100-2e2023 identifies five kinds of privacy attacks: data reconstruction, memorization, membership inference, model extraction, and property inference.
-
Data reconstruction - the attacker reverse engineers confidential information about an individual user or other sensitive data from access to aggregate statistical information. This is the most concerning privacy attack, according to the authors of the NIST report.
-
Memorization - the attacker tries to extract training data from generative ML models, for instance by inserting synthetic canaries in the training data and then extracting it.
-
Membership inference - the attacker tries to determine if a particular record or data sample is part of the training dataset.
-
Model extraction - the attacker tried to extract information about model architecture and parameters by submitting queries to the ML model. This class of attack is especially aimed at ML models trained by a MLaaS provider.
-
Property inference - the attacker tries to learn global information - e.g., confidential, demographic information - about the training data distribution by interacting with an ML model.
Conclusion
This blog post has only scratched the surface of NIST AI 100-2e2023. Readers who are interested in more details about the taxonomy outlined above, not to mention mitigation strategies, are encouraged to study the report.
It goes without saying that developers of AI systems would want to harden their technologies against the attacks outlined above, so as to make their systems more trustworthy. At the same time, presumably, AI developers want to maximize the performance of their models. A troubling conclusion of NIST AI 100-2e2023 is that is might not be possible to simultaneously maximize the performance of an AI system and attributes that contribute to the trustworthiness of the system, in particular adversarial robustness.
Concerned about the security of your AI tools? Schedule some time to talk with one of our experts.